Controllable image generation methods, such as ControlNet, have demonstrated a remarkable capacity
to introduce visual conditions (e.g., depth maps) to guide image generation. However,
these methods often struggle with complex multi-instance scenes, frequently leading to
attribute confusion among instances. While recent approaches attempt to mitigate
this via manual instance labeling, such requirements are labor-intensive.
In this paper, we propose InstanceControl, a novel
multi-instance controllable generation method that eliminates the need for instance
labeling. We identify the primary bottleneck in existing methods as the inability to
accurately associate instance descriptions with their corresponding regions within visual conditions.
To address this, we leverage the Vision-Language Model (VLM) to establish
instance-level correspondences between text prompts and visual conditions. Specifically, the VLM
automatically parses instance descriptions from the text prompts and simultaneously predicts
instance masks based on the visual conditions. Furthermore, since the predicted masks may contain
noise, we introduce an adaptive mask refinement strategy that dynamically refines
these instance masks during the generation process. Extensive experiments demonstrate that our
approach outperforms state-of-the-art methods, achieving superior fidelity and precise
instance-level control.
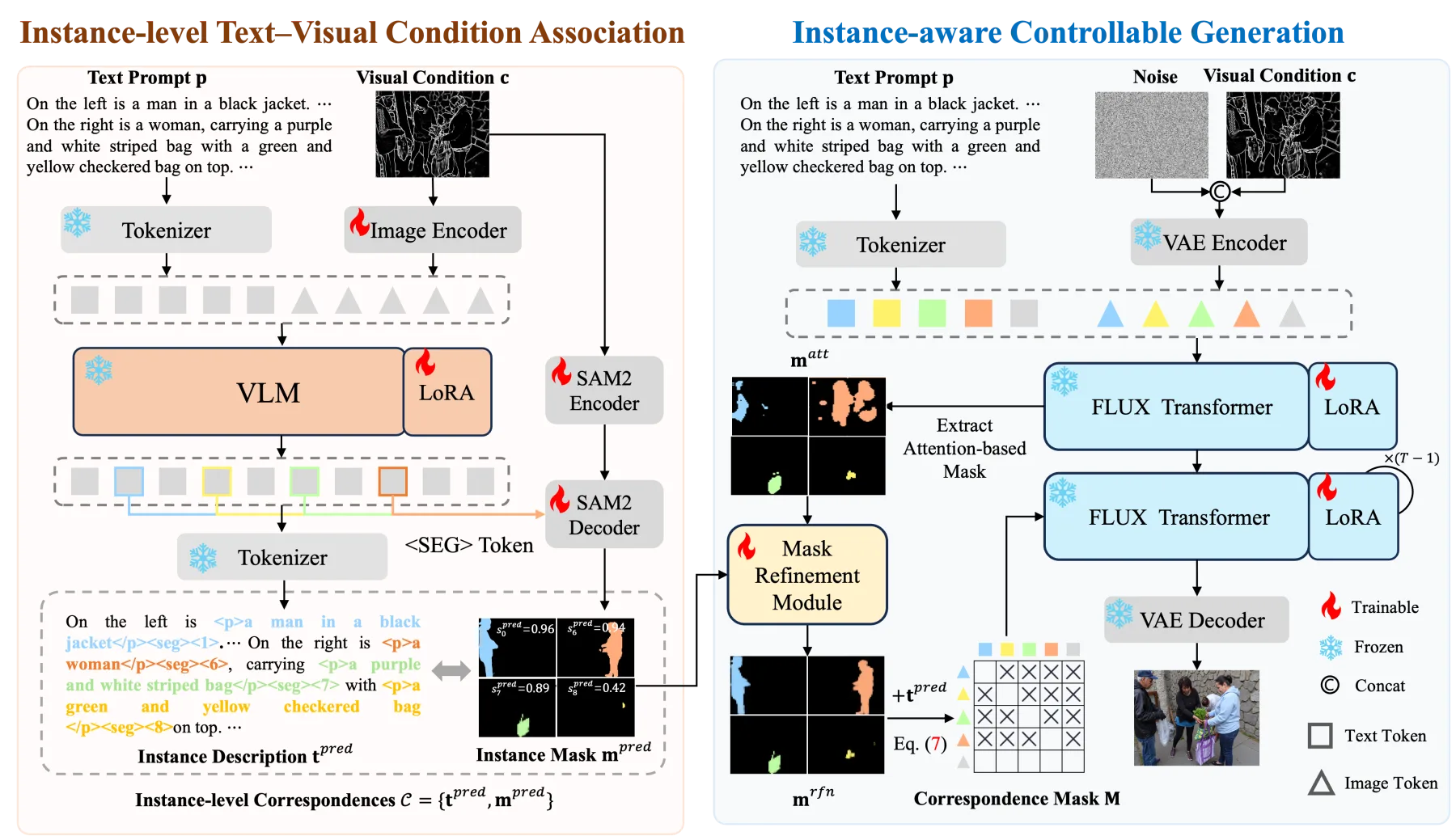
Methodology
Figure 1. Overview of InstanceControl. Our framework consists of two core stages:
(1) instance-level text-visual condition association via VLM, and
(2) instance-aware controllable generation with adaptive mask refinement.
Experimental Results
Table 1: Quantitative Comparison on Multi-Instance Controllable Generation
Setting
Methods
MIoU↑
Region-wise Quality
Global-wise Quality
Local CLIP↑
Spatial↑
Color↑
Shape↑
Texture↑
IR↑
FID↓
w/ Instance Labeling
EliGen
0.6104
17.49
91.97%
84.98%
85.59%
87.93%
0.3708
27.8240
CreatiLayout
0.5247
16.84
88.16%
80.87%
83.00%
85.91%
0.2979
21.3988
Seg2Any
0.8316
18.62
91.71%
87.25%
88.39%
90.14%
0.0893
21.2305
DreamRenderer (Canny)
0.6497
16.25
80.74%
67.55%
69.20%
74.68%
0.1877
14.5079
InstanceControl (Canny)
0.8381
18.97
95.34%
92.11%
92.29%
93.66%
0.2940
9.9340
DreamRenderer (Depth)
0.7738
17.88
89.52%
80.91%
81.45%
86.69%
0.3206
15.3637
InstanceControl (Depth)
0.8212
18.73
95.06%
91.35%
92.08%
93.47%
0.2921
11.9211
DreamRenderer (HED)
0.7060
15.08
78.93%
60.56%
63.18%
68.79%
0.0392
22.6739
InstanceControl (HED)
0.8504
19.08
95.77%
92.58%
92.77%
94.10%
0.3256
10.2175
w/o Instance Labeling
FLUX ControlNet (Canny)
0.6526
16.48
84.67%
73.30%
73.93%
79.24%
0.2558
14.0427
InstanceControl (Canny)
0.8250
18.51
93.54%
87.78%
88.19%
90.88%
0.2847
10.0264
FLUX ControlNet (Depth)
0.7782
17.73
90.14%
75.87%
78.20%
82.33%
0.3216
14.1077
InstanceControl (Depth)
0.8116
18.18
92.87%
86.11%
86.49%
89.91%
0.2961
11.9181
FLUX ControlNet (HED)
0.6817
15.67
83.09%
70.15%
70.51%
77.08%
0.2314
20.0755
InstanceControl (HED)
0.8472
18.74
94.64%
88.75%
89.55%
91.18%
0.3268
10.14
Comparison with state-of-the-art methods on multi-instance controllable generation across three visual conditions (Canny, Depth, HED).
Bold values indicate the best result within each group.
IR denotes Instance Reward. FID measures global image quality (lower is better).
InstanceControl achieves the best performance in both settings, even surpassing methods that require instance labeling.
Qualitative Comparison
Click or hover over any instance text or image region to highlight the corresponding object
Text Prompt
Condition
😢 ControlNet
😊 Ours
😢
😊
Visualization of Learned Correspondences
Hover over any instance text or image region to highlight the corresponding object